
Cell子刊:上科大刘雪松团队开发DeepMeta模型,为不可成药癌症预测代谢靶点
时间:2025-07-14
来源:生物世界 2025-07-13 13:05
该研究开发了一种基于图深度学习的代谢脆弱性预测模型——DeepMeta,能够基于转录组和代谢网络信息准确预测癌症样本的依赖代谢基因,可为那些具有不可成药驱动突变的癌症提供代谢靶点。的代谢重编程与肿瘤进展的若干过程密切相关,包括肿瘤细胞的转化启动、增殖和转移,被认为是癌症的特征之一。代谢重编程提高了肿瘤细胞的适应性,并赋予它们相对于其他细胞的选择性优势,从而增加了肿瘤细胞在应激条件下存活的概率。反过来,这些代谢适应使得依赖于特定的代谢途径,从而产生可进行治疗性探索的弱点。
基因突变是癌症的主要驱动因素,一些癌症驱动基因突变(例如 EGFR-L858R 和 BRAF-V600E)已成功开发药物。然而,还有许多反复出现的癌症驱动基因突变(例如 CTNNB1、MYC 和 TP53)会产生缺乏小分子能高亲和力结合的可及性疏水口袋的突变蛋白,因此被认为是不可成药靶点或难成药靶点。
许多癌症驱动基因突变可导致代谢改变,因此,通过利用代谢依赖性间接靶向这些癌症驱动基因突变可能是一种有吸引力的癌症治疗策略。然而,针对癌细胞这些代谢脆弱性的系统性研究,仍显不足。
近日,上海科技大学刘雪松团队在 Cell 子刊Cell Reports上发表了题为:Precise metabolic dependencies of cancer through deep learning and validations的研究论文。
该研究开发了一种基于图深度学习(Graph Deep Learning)的代谢脆弱性预测模型 DeepMeta,能够基于转录组和代谢网络信息准确预测癌症样本的依赖代谢基因,可为那些具有不可成药驱动突变的癌症提供代谢靶点。

癌细胞表现出代谢重编程以维持其增殖,这也产生了正常细胞中不存在的代谢弱点。虽然之前的一些研究确定了癌细胞中特定的代谢依赖性,但仍缺少系统性见解。
在这项新研究中,研究团队构建了一个基于图深度学习(Graph Deep Learning)的代谢脆弱性预测模型 DeepMeta,该模型能够基于转录组和代谢网络信息准确预测癌症样本的依赖代谢基因。
DeepMeta 的性能已通过独立数据集得到了广泛验证。研究团队使用DeepMeta,通过癌症基因组图谱(TCGA)数据集,对 不可成药 的癌症驱动性改变的代谢脆弱性进行了系统性探索。值得注意的是,实验已证实 CTNNB1 T41A 激活突变对嘌呤/嘧啶代谢抑制剂具有敏感性。从 TCGA 中预测出嘧啶代谢依赖性的患者对阻断该嘧啶代谢途径的化疗药物表现出显著改善的临床反应。
该研究的亮点:
DeepMeta 能够预测个体癌症患者的代谢脆弱性; 核苷酸代谢和谷胱甘肽代谢表现出泛癌代谢依赖性; DeepMeta 预测具有不可成药驱动突变的癌症的代谢脆弱性。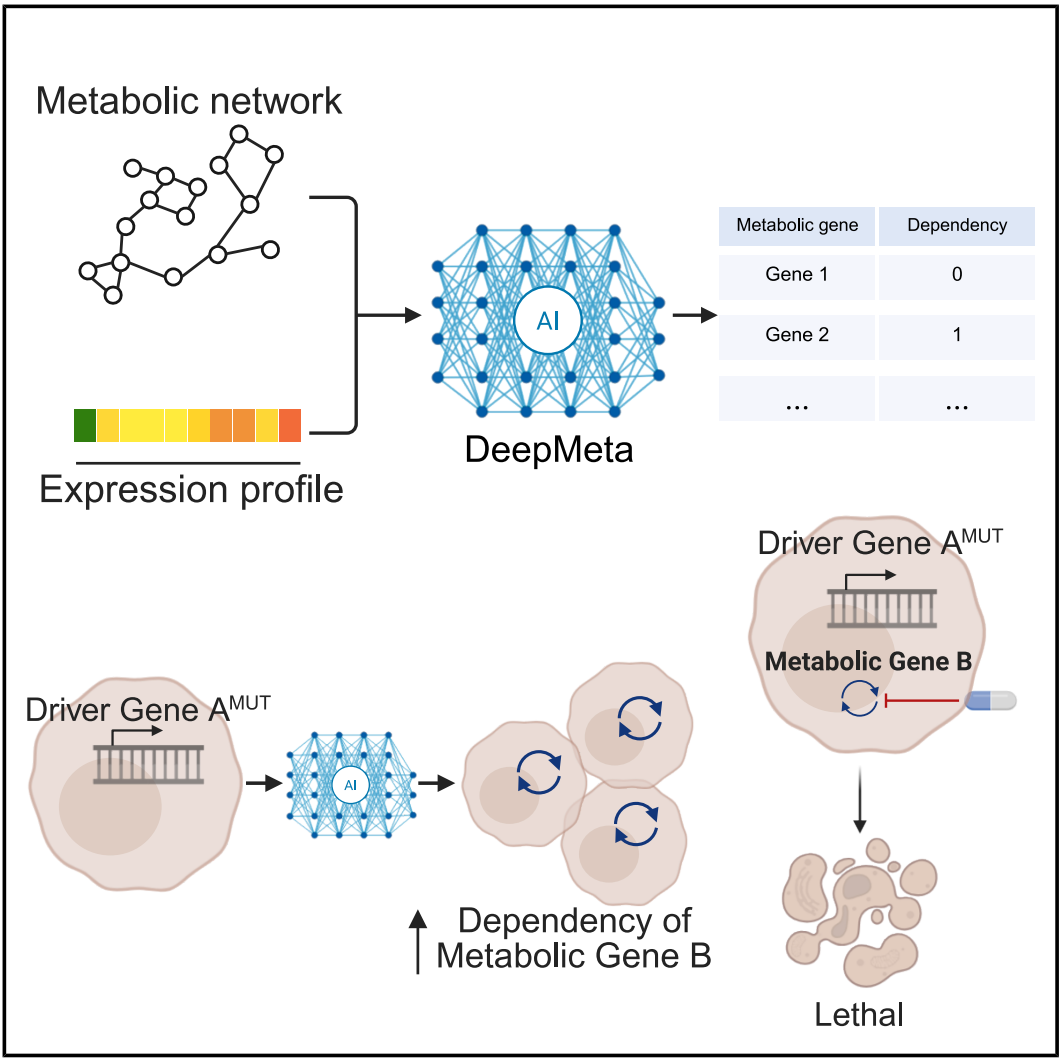
总的来说,这项研究系统性地揭示了癌细胞的代谢依赖性,并为那些由基因突变驱动的癌症提供了代谢靶点,这些基因突变本身原本属于不可成药靶点。
版权声明 本网站所有注明“来源:100医药网”或“来源:bioon”的文字、图片和音视频资料,版权均属于100医药网网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:100医药网”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。 87%用户都在用100医药网APP 随时阅读、评论、分享交流 请扫描二维码下载->